Loading... 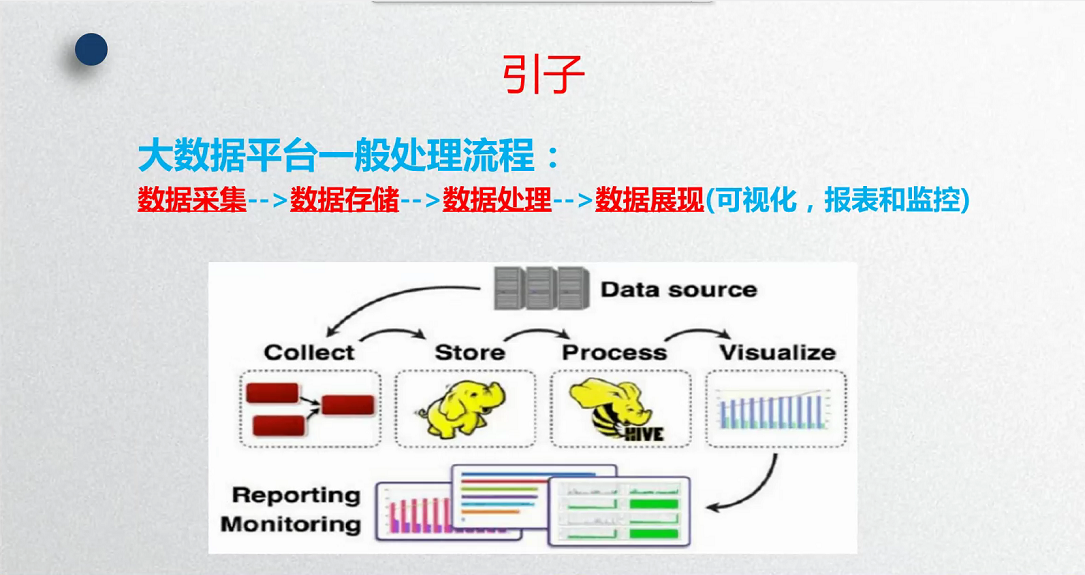 ## 采集步骤 - python 爬虫 ```python import requests headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36'} # 传入url和请求头 r = requests.get('https://www.zhihu.com/question/292367995/answer/480676785',headers=headers) print(r.text) ``` 关于浏览器版本: ```txt Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36 ``` 对于google,我们可以在 chrome://version/ 这个路径查找 或则 在浏览器设置里面找,不同浏览器的代理是不同的。 - 提取需要的信息 ```python from lxml import etree # 将html文档转换为XPath可以解析的 s = etree.HTML(r.text) # 获取问题内容 q_content = s.xpath('//*[@class="QuestionHeader-title"]//text()')[0] # 打印 print(' 问题:',q_content,'\n') ``` ## 大数据预处理  - 平滑方式  最后修改:2021 年 11 月 21 日 © 禁止转载 打赏 赞赏作者 支付宝微信 赞 如果觉得我的文章对你有用,请随意赞赏
