Loading... # 1、每种数据类型的应用场景 - String 这个其实没啥好说的,最常规的set/get操作,value可以是String也可以是数字。一般做**一些复杂的计数功能的缓存。** - hash 这里value存放的是结构化的对象,比较方便的就是操作其中的某个字段。在做**单点登录**的时候,就是用这种数据结构存储用户信息,以cookieId作为key,设置30分钟为缓存过期时间,能很好的模拟出类似session的效果。 - list 使用List的数据结构,可以**做简单的消息队列的功能**。另外还有一个就是,可以利用lrange命令,**做基于redis的分页功能**,性能极佳,用户体验好。 - set 因为set堆放的是一堆不重复值的集合。所以可以做**全局去重的功能**。为什么不用JVM自带的Set进行去重?因为我们的系统一般都是集群部署,使用JVM自带的Set,比较麻烦,难道为了一个做一个全局去重,再起一个公共服务,太麻烦了。 另外,就是利用交集、并集、差集等操作,可以**计算共同喜好,全部的喜好,自己独有的喜好等功能**。 - sorted set sorted set多了一个权重参数score,集合中的元素能够按score进行排列。可以做**排行榜应用,取TOP N操作**。 # 2、过期策略及内存淘汰机制 ## 分析: 如果你的redis只能存5G数据,可是你写了10G,那会删5G的数据。怎么删的?还有,你的数据已经设置了过期时间,但是时间到了,内存占用率还是比较高,怎么办? **回答**: redis采用的是**定期删除+惰性删除策略**。 ## 为什么不用定时删除策略? 定时删除,用一个定时器来负责监视key,过期则自动删除。虽然内存及时释放,但是十分消耗CPU资源。在大并发请求下,CPU要将时间应用在处理请求,而不是删除key,因此没有采用这一策略. ## 定期删除+惰性删除是如何工作的呢? 定期删除,redis默认每个100ms检查,是否有过期的key,有过期key则删除。需要说明的是,redis不是每个100ms将所有的key检查一次,而是随机抽取进行检查(如果每隔100ms,全部key进行检查,redis岂不是卡死)。因此,如果只采用定期删除策略,会导致很多key到时间没有删除。 于是,惰性删除派上用场。也就是说在你获取某个key的时候,redis会检查一下,这个key如果设置了过期时间那么是否过期了?如果过期了此时就会删除。 ## 采用定期删除+惰性删除就没其他问题了么? 不管是定期删除还是惰性删除,都是一种不完全精确的删除策略,始终还是会存在已经过期的key无法被删除的场景。而且这两种过期策略都是只针对设置了过期时间的key,不适用于没有设置过期时间的key的淘汰,所以,Redis还提供了内存淘汰策略,用来筛选淘汰指定的key。 # 3、Redis 的存储原理 ## 3.1 存储结构 Redis 的存储方式使用的是散列表的形式,我们都知道,数据结构的最底层物理结构只有数组和链表,而其他的比如说队列、树、图等数据结构都是基于这两个物理结构所实现的逻辑数据结构。 而数组和链表的区别主要在于读写的时间复杂度和内存的拓容上,因为数组要拓容的成本很高,因此大多数情况下会选用链表来实现各种逻辑数据结构。  在 Redis 的底层存储中,会维护一个全局的哈希表(本质上就是数组),它有无数个哈希桶(数组元素)组成,每一个哈希桶的存储了两个指针,一个是指向 key 的指针,另一个则是指向 value 的指针。目前 Redis 的 key 只有一种形式,就是字符串,而 value 却有多种支撑,包括 字符串类型,列表,哈希,集合,有序集合。我们知道数组取下标元素的时间复杂度为 O(1), 因为想要获得获取对应的哈希桶,实际上消耗的时间是哈希函数的计算,这个计算和哈希桶的数据量是没有关系的,一般来说哈希函数对应的时间复杂度为 O(1)。这种设计十分的巧妙,把资源放在其他地方,只保留对应资源的指针,在维护上会有很大的便捷性,这就好比说,我不需要把货物都放在房子里,我只需要一张纸,记录着我的每个货物的位置即可。这相当于MySQL 的表结构和数据分开存储有异曲同工之处。 ## 3.2 rehash 学过数据结构的同学都知道,没有一个绝对无敌的哈希函数可以实现无冲突处理,而一般来说解决冲突的方式有两大类(注意这里是分的大类),一个是开放地址法,另一个是链地址法。而 Redis 采用的正是第二种方式。 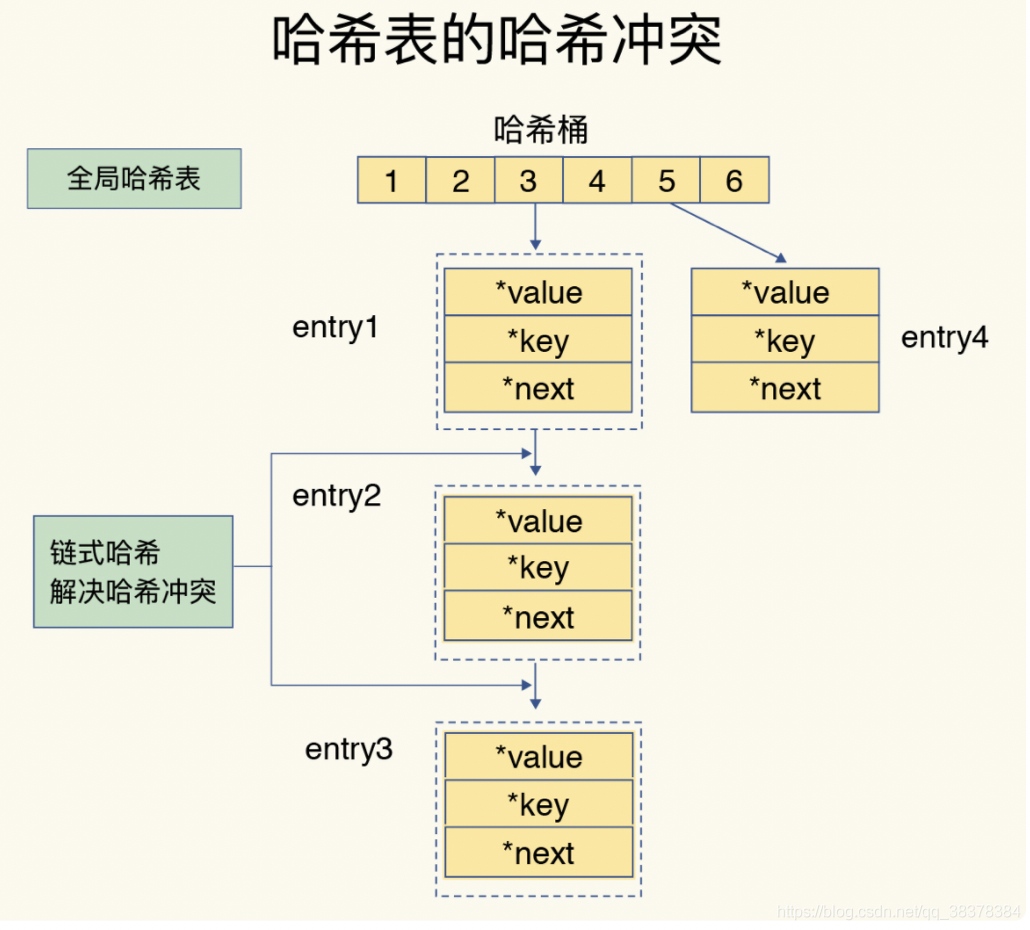 当存在冲突的时候,会将对应的冲突实体放在一起搞成一个链表,此时哈希桶的指针会增加一个next 指针,用来指向下一个冲突实体,当数据量足够大的时候,这个链表可能会被拉的越来越长,因为链表的查询只能从头结点开始遍历下去,也就是 O(n) 的复杂度(n为链表长度),所以当链表过长时,会影响最终的查询速度。所以这时候不能袖手旁观。 因此,在这种情况下,Redis 会有另外一个线程专门去处理。我们称这种方式为 rehash ,和很多语言的数组底层一样,这种rehash 机制也是基于复制状态机的,说白了就是申请另一块空间(通常是原来的两倍),然后把数据信息复制过去,再释放原来的空间。通常来说程序不会快死的时候才想着救自己,当数值达到预警值时,就会开始自救,我们常常将其称之为装填因子,计算方式十分的简单,就是 use/total, 不同的存储对装填因子的判断规则不同,内容也比较底层,这里我们就不展开叙述了。 所以在 Redis 中,会存在另一张全局哈希表,其实它就是一个备胎,每次需要拓容的时候,这个备胎往往空间要比原配更大,rehash 线程会将原配的数据复制到备胎中,然后备胎就可以转正了。但是在复制的过程中,会有两个问题,一个是内存占用率会突然飙升,另一个就是Redis 阻塞的问题,复制的操作又耗时又耗空间,因此我们还需要更加聪明一点,能不能让一次的操作分成多步呢?温水煮青蛙,如果每次来一个请求我就迁徙一点,这样的话,是不是慢慢的我就复制完了。这就是 Redis 的渐进式 rehash。 ## 3.3 渐进式 rehash 两个人的感情是需要慢慢的培养的,程序的处理也是可以慢慢来的,有些事情并不非要一次性搞完的,我们首先需要知道,Redis 是怎么去渐进式 rehash的,假设我要取 key 为 csdn 的 value ,而通过hash 算法得到的 索引位置为 1,但是该索引上有一个三个 entry, 此时处理的线程正常的去遍历这个链表拿到真正正确的值,此时 rehash进程 顺便把这个索引的 entry 从 ht0 复制到 ht1 中。并且释放 ht0 该索引的空间。大致流程如下图所示: 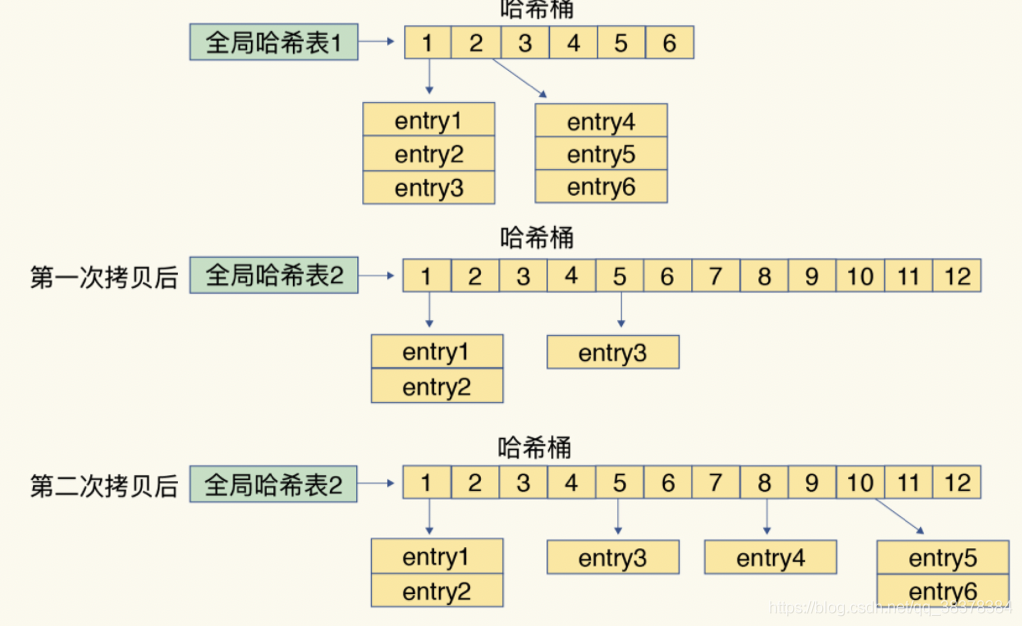 这时候我们就会纠结一个问题了,如果有两种全局哈希表,那么Redis 的 crud 是怎么去操作的呢? Redis的删除、查找、更新等操作会在两个全局哈希表上进行,比如说, 要在字典里面查找一个键的话, 程序会先在 ht0 里面进行查找, 如果没找到的话, 就会继续到 ht1 里面进行查找,并且新添加到Redis的键值对一律会被保存到 ht[1] 里面, 而 ht[0] 则不再进行任何添加操作: 这一措施保证了 ht[0] 包含的键值对数量会只减不增, 并随着 rehash 操作的执行而最终变成空表,就完成了备胎转正流程。 # 4、缓存穿透、缓存击穿、缓存雪崩 在介绍这三大问题之前,我们需要先了解Redis作为一个缓存中间件,在项目中是如何工作的。首先看一下在没有缓存中间件的时候的系统数据访问的架构图: 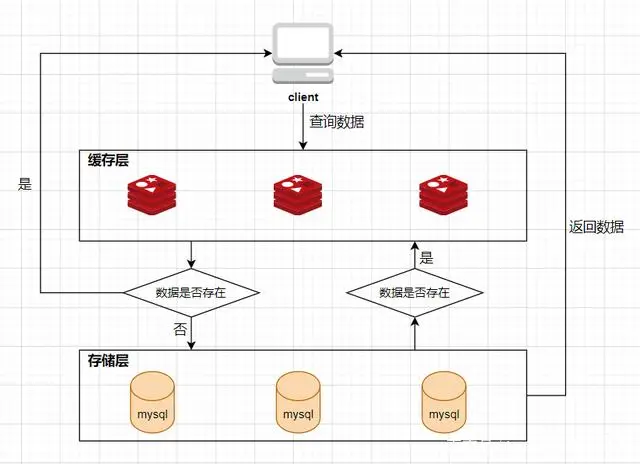 客户端发起一个查询请求的时候,首先去缓存中查询,如果数据在缓存中存在,则直接将缓存中的数据返回给客户端;如果数据在缓存中不存在,则继续查询数据库,如果数据在数据库中存在,则将该数据放入缓存中,并返回给客户端,如果数据在数据库中也不存在,则直接返回null给客户端。 ## 4.1、缓存穿透 缓存穿透是指查询一个缓存中和数据库中都不存在的数据,导致每次查询这条数据都会透过缓存,直接查库,最后返回空。当用户使用这条不存在的数据疯狂发起查询请求的时候,对数据库造成的压力就非常大,甚至可能直接挂掉。这种情况的流程就变成下图这样了: 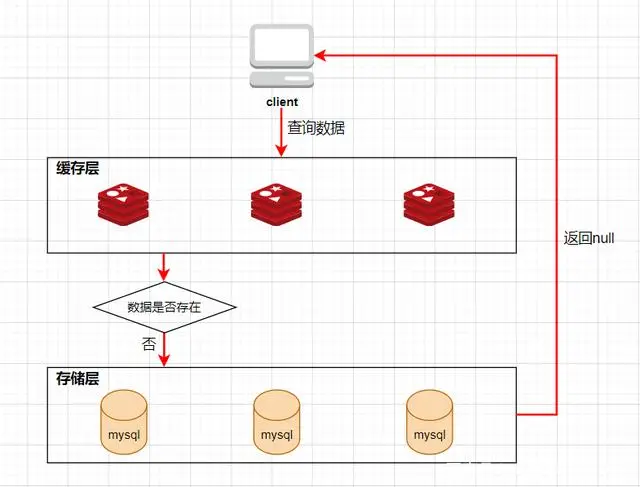 > 解决缓存穿透的方法一般有两种, - 第一种是缓存空对象, - 第二种是使用布隆过滤器。 第一种方法比较好理解,就是当数据库中查不到数据的时候,我缓存一个空对象,然后给这个空对象的缓存设置一个过期时间,这样下次再查询该数据的时候,就可以直接从缓存中拿到,从而达到了减小数据库压力的目的。但这种解决方式有两个缺点:(1)需要缓存层提供更多的内存空间来缓存这些空对象,当这种空对象很多的时候,就会浪费更多的内存;(2)会导致缓存层和存储层的数据不一致,即使在缓存空对象时给它设置了一个很短的过期时间,那也会导致这一段时间内的数据不一致问题。 第二种方案是使用布隆过滤器,这是比较推荐的方法。所谓布隆过滤器,就是一种数据结构,它是由一个长度为m bit的位数组与n个hash函数组成的数据结构,位数组中每个元素的初始值都是0。在初始化布隆过滤器时,会先将所有key进行n次hash运算,这样就可以得到n个位置,然后将这n个位置上的元素改为1。这样,就相当于把所有的key保存到了布隆过滤器中了。 举个例子,比如我们一共有3个key,我们对这3个key分别进行3次hash运算,key1经过三次hash运算后的结果分别为2/6/10,那么就把布隆过滤器中下标为2/6/10的元素值更新为1,然后再分别对key2和key3做同样操作,结果如下图: 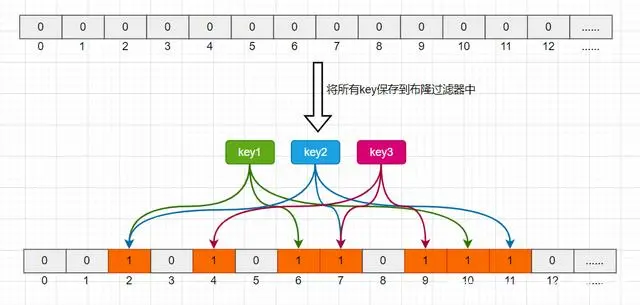 这样,当客户端查询时,也对查询的key做3次hash运算得到3个位置,然后看布隆过滤器中对应位置元素的值是否为1,如果所有对应位置元素的值都为1,就证明key在库中存在,则继续向下查询;如果3个位置中有任意一个位置的值不为1,那么就证明key在库中不存在,直接返回客户端空即可。如下图: 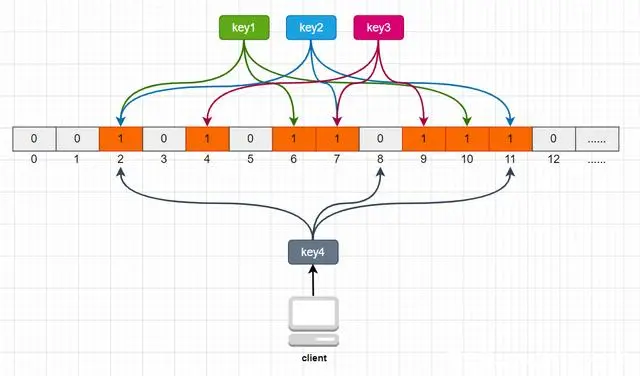 当客户端查询key4时,key4的3次hash运算中,有一个位置8的值为0,就说明key4在库中不存在,直接返回客户端空即可。 所以,布隆过滤器就相当于一个位于客户端与缓存层中间的拦截器一样,负责判断key是否在集合中存在。如下图: 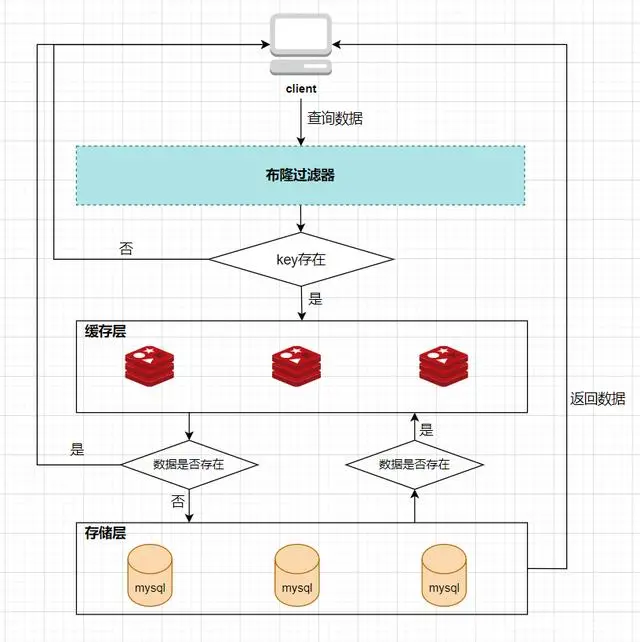 布隆过滤器的好处就是解决了第一种缓存空值的不足,但布隆过滤器也存在缺陷,首先,它有误判的可能,比如在上面客户端查询key4的图中,假如key4经过3次hash运算得到的位置分别是2/4/6,由于这3个位置的值都是1,所以,布隆过滤器就认为key4在库中存在,进而继续向下查询了。所以,布隆过滤器判断存在的key实际上可能是不存在的,但布隆过滤器判断不存在的key是一定不存在的。它的第二个缺点就是删除元素比较难,比如现在要删除key2这个元素,那么需要将2/7/11三个位置的元素值改为0,但这样就会影响到key1和key3的判断。 ## 4.2、缓存击穿 缓存击穿是指当缓存中某个热点数据过期了,在该热点数据重新载入缓存之前,有大量的查询请求穿过缓存,直接查询数据库。这种情况会导致数据库压力瞬间骤增,造成大量请求阻塞,甚至直接挂掉。 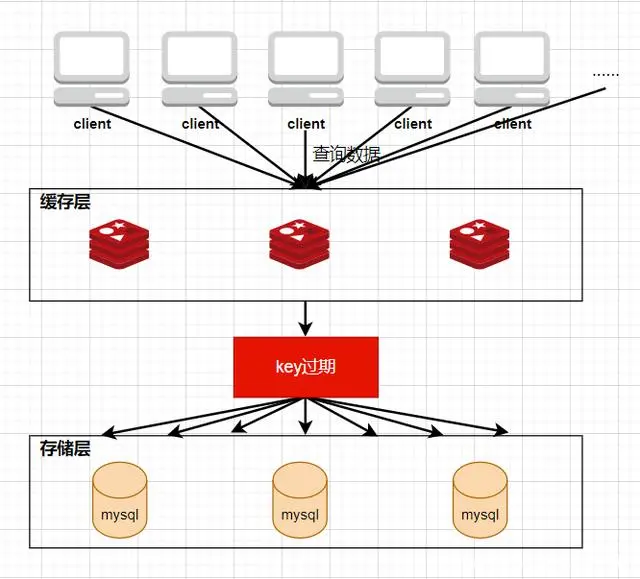 ### 缓存击穿解决方案 解决缓存击穿的方法也有两种; - 第一种是设置key永不过期;在设置热点key的时候,不给key设置过期时间即可。第二方式也可以达到key不过期的目的,就是正常给key设置过期时间,不过在后台同时启一个定时任务去定时地更新这个缓存。  - 第二种方式使用了加锁的方式,锁的对象就是key,这样,当大量查询同一个key的请求并发进来时,只能有一个请求获取到锁,然后获取到锁的线程查询数据库,然后将结果放入到缓存中,然后释放锁,此时,其他处于锁等待的请求即可继续执行,由于此时缓存中已经有了数据,所以直接从缓存中获取到数据返回,并不会查询数据库。  ## 4.3、缓存雪崩 缓存雪崩是指当缓存中有大量的key在同一时刻过期,或者Redis直接宕机了,导致大量的查询请求全部到达数据库,造成数据库查询压力骤增,甚至直接挂掉。  ### 缓存雪崩解决方案 - 1、将失效时间分散开 通过使用自动生成随机数使得key的过期时间是随机的,防止集体过期 - 2、使用多级架构 使用nginx缓存+redis缓存+其他缓存,不同层使用不同的缓存,可靠性更强 - 3、设置缓存标记 记录缓存数据是否过期,如果过期会触发通知另外的线程在后台去更新实际的key - 4、使用锁或者队列的方式 如果查不到就加上排它锁,其他请求只能进行等待 # 9、springboot整合redis 依赖: ```xml <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> <version>2.3.12.RELEASE</version> </dependency> ``` ```java public String redisTest(String username){ ValueOperations valueOperations = redisTemplate.opsForValue(); valueOperations.set("user",username); valueOperations.set("userInfo","lutiancheng",1000, TimeUnit.MICROSECONDS); return valueOperations.get("user").toString(); } ``` 最后修改:2023 年 03 月 08 日 © 允许规范转载 打赏 赞赏作者 支付宝微信 赞 1 如果觉得我的文章对你有用,请随意赞赏
